第六章 流量控制
关于上一章
上一章节讨论了主要的三种类型的数据包:TLP 事务层包(Transaction Layer Packets)、DLLP 数据链路层包(Data Link Layer Packets)、Ordered Sets 命令集。并且在上一章中主要讲述 TLP 的用法、格式和不同种类的定义,并将详细的讲解 TLP 的相关字段含义。关于 DLLP 的内容将会在 Chapter 9 “DLLP Element”中进行单独讲解。
关于本章
本章节将讨论流量控制协议(Flow Control)的目的以及细节操作。流量控制是用来确保在接收者无法接收 TLP 时,发送方不会再继续发送 TLP。这避免了接收 Buffer 溢出,也消除了原本 PCI 工作方式中的一些低效行为,比如断开(disconnect)、重试(retry)和等待态(wait-state)。
关于下一章
下一章节将会讨论用于支持 QoS(Quality of Service)的机制,并描述对网络结构中传输的不同数据包的传输时间和带宽进行控制的意义。这些机制包括,特定应用的软件将会给每个数据包都分配优先级,以及每个设备内构建可选的硬件来启用事务优先级管理。
6.1 流量控制概念(Flow Control Concept)
每条 PCIe 链路两端的端口都必须实现流量控制机制。在一个数据包允许被发出之前,流量控制机制必须确认接收端口拥有足够的可用 Buffer 空间来接收数据包。而在像 PCI 这种并行总线中,尽管不知道目标方是否准备好了处理数据,事务也会尝试去发送执行,如果因为没有足够的可用 Buffer 空间,请求被拒绝了,那么事务就会一直重试(Retry)直至完成。这就是 PCI 的“Delayed Transaction Model 延迟的事务模型”,然而这种方式的效率很低。
流量控制机制可以改善当多个虚拟通道(Virtual Channel,VC)被占用时的传输效率。每个虚拟通道自己的事务是与其他 VC 的事务流量相独立的,因为流量控制 Buffer 是 VC 各自单独维护的。因此,若一个 VC 的流控 Buffer 满了,它也不会阻塞对其他 VC Buffer 的访问。PCIe 支持最多 8 条虚拟通道。
流量控制机制使用一种基于信用(Credit-based)的机制,使得发送端口可以知道接收端口有多少可用的 Buffer 空间。作为它们初始化的一部分,每个接收者都要将自己的 Buffer 大小报告给链路对端的发送者,并在运行过程中使用 DLLP 来定期地更新这个“信用值”。技术上来说,DLLP 显然是一种开销,因为它并不携带任何数据荷载,但是 DLLP 开销很小(始终为 8 个符号大小),这样可以使其对性能的影响最小。
流量控制逻辑实际上是两个层级的共同职责:事务层包含了计数器用于对可用 Buffer 空间进行计数,但是数据链路层也要负责发送和接收这些包含了可用 Buffer 空间信息的 DLLP。如图 6‑1 展示了这种共同职责。在流量控制的的工作过程中:
-
设备报告可用的 Buffer 空间:接收者的每个端口都要报告自己的流量控制 Buffer 的大小,单位为 credit(信用)。一个 Buffer 中 credit 的数量会从自身接收侧事务层发送至发送侧数据链路层(如图 6‑1)。在合适的时间,数据链路层将会产生一个流量控制 DLLP 来将这个 credit 信息转发至每个流量控制 Buffer 的链路对端的接收者的。
-
接收者寄存 Credit:接收者收到流量控制 DLLP,并将 credit 值传输至自身发送侧事务层。这就完成了 credit 从链路的一端到对端的传输。这些操作是双向进行的,直到所有的流量控制信息都完成了交换。
-
发送者检查 Credit:在发送者可以发送一个 TLP 之前,它需要检查流量控制计数器(Flow Control Counter),以此来知道对方是否有足够的 credit。如果 credit 数量足够,那么就将 TLP 转发至数据链路层,但是如果 credit 不足,那么 TLP 的发送操作就会被阻塞直至获知的更多的足够的流量控制 credit。
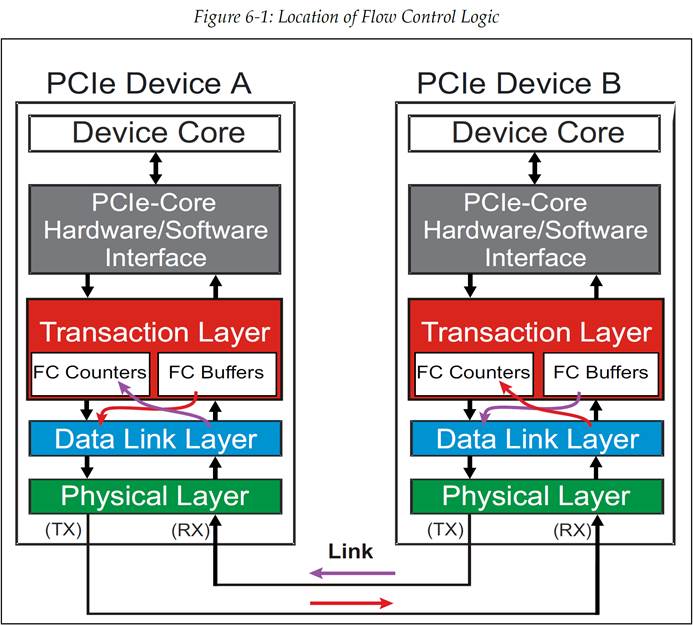
图 6‑1 流量控制逻辑所处的位置
6.2 流量控制 Buffer 和 Credit(Flow Control Buffer and Credits)
一个端口所支持的每个 VC(Virtual Channel)资源都会实现流量控制 Buffer。回想一下,链路两端的端口可能支持的 VC 数量是不同的,因此由软件进行配置和启用的 VC 的最大数量就是两个端口间的最大公共 VC 数量。
6.2.1 VC 流量控制 Buffer 的组成(VC Flow Control Buffer Organization)
接收者的每个 VC 流控 buffer 是按照通过 VC 的每种事务类别来进行管理的。这些类别为:
除此之外,每个既有 Header 也有数据荷载的事务类别,都会被分成 Header 和数据两部分。这将产出 6 种不同的 Buffer,每个 Buffer 都实现自己的流控。(见图 6‑2)。
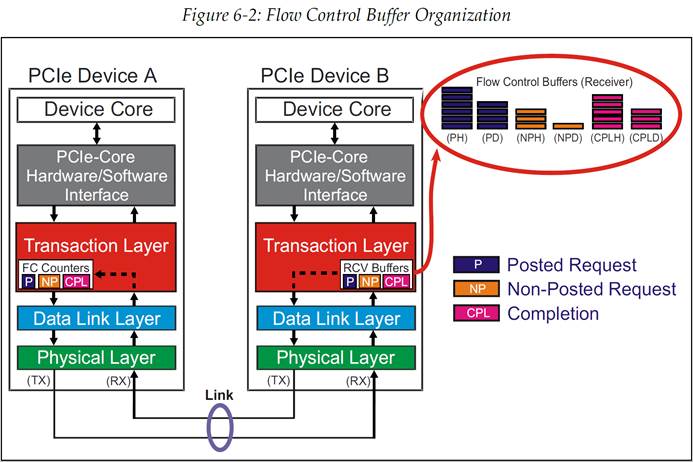
图 6‑2 流控 Buffer 组成
对于有些事务,例如读请求,它只由 Header 组成,而像写请求就既有 Header 也有数据荷载。发送者必须确认 Header 的 Buffer 空间和数据荷载的 Buffer 空间都满足了事务传输的需求,才能发送事务。注意,当事务被转发至软件或者是在 Switch 中被转发至出口端口时,必须在 VC 流控 Buffer 中保持事务顺序。因此,接收者也必须跟踪 Buffer 内的 Header 和数据荷载的顺序。
6.2.2 流控 Credit(Flow Control Credits)
接收者需要报告 Buffer 空间的大小,使用的单位是 Credit,或者叫流量控制 Credit。Header 和数据荷载 Buffer 的一个流控 Credit(FCC,Flow Control Credit)的大小值分别为:
- Header Credit:Header 大小的最大值+digest
— 完成包为 4DW
— 请求包为 5DW
流量控制 DLLP 会传达这个信息,而 DLLP 自身的传输是不需要流控 Credit 的。这是因为 DLLP 产生和终结的地方都是在数据链路层,并不需要使用到事务层 Buffer。
6.3 初始流量控制通告(Initial Flow Control Advertisement)
在流控的初始化过程中,PCIe 设备们会通过对 Buffer 空间的流控 Credit 进行“advertising 通告”的方式,来相互传达各自的 Buffer 大小。PCIe 也专门定义了一些 Buffer 需要的流控 Credit 初始值。一个通告过自己的初始 Buffer 空间的接受者,可以有效的保证它的 Buffer 空间永远不会溢出。
6.3.1 流控通告的最大值和最小值(Minimum and Maximum Flow Control Advertisement)
协议规范定义了各种不同的流控 Buffer 类型所报告的 Credit 数量的最小值,表 6‑1 列出了这些 Buffer 类型对应的 Credit 最小值。然而,设备一般通告的 Credit 数量会远大于最小值,表 6‑2 列出了协议所允许的 Credit 数量通告的最大值。
| Credit 类型 |
通告(Advertisement)最小值 |
| Posted Request Header (PH) <br/>Posted 请求 Header |
1 单位: Credit 值= 1 个 4DW Header+Digest= 5DW |
| Posted Request Data (PD) <br/>Posted 请求数据 |
这个值是 Max_Payload_Size 的最大值用 Credit 的表示。 <br>例如:如果支持的最大的 Max_Payload_Size 为 1024Byte,那么允许的最小的初始 Credit 值就是 040h(64*16byte)。 |
| Non-Posted Request Header (NPH) <br/>Non-Posted 请求 Header |
1 单位: Credit 值= 1 个 4DW Header+Digest= 5DW |
| Non-Posted Request Data (NPD) <br/>Non-Posted 请求数据 |
1 单位: Credit 值= 1 个 4DW Header+Digest= 5DW <br/>2 单位: 如果接收方支持 AtomicOP 路由或者具有作为 AtomicOP 完成者的能力,那么 Credit 值可以为 02h。 |
| Completion Header (CplH) <br/>完成包 Header |
1 单位: Credit 值= 1 个 3DW Header+Digest= 4DW。这种情况是对于支持 Peer-to-Peer 的 RC 和 Switch。 <br/>无限数量:初始 Credit 值=全 0。应用于不支持 Peer-to-Peer 的 RC 和 EP。 |
| Completion Data (CplD) <br/>完成包数据 |
n 单位: 这个值是 Max_Payload_Size 或者是读请求 size 这二者可能的最大值(一般读请求 size 会比前者小)除以 FC 单位大小(4DW)。这种情况是对于支持 Peer-to-Peer 的 RC 和 Switch。 <br/>无限数量:初始 Credit 值=全 0。应用于不支持 Peer-to-Peer 的 RC 和 EP。 |
表 6‑1 流控通告最小值
| Credit 类型 |
通告(Advertisement)最大值 |
| Posted Request Header (PH) <br/>Posted 请求 Header |
128 单位: 128 Credits=128*5DW=2560 Bytes |
| Posted Request Data (PD) <br/>Posted 请求数据 |
2048 单位: 值为设备支持多有 Function(8 个)的 Max_Payload_Size(4096 bytes)总和,<br/>总和为 8x4096=32768,除以 Credit 大小(4DW)。<br/>2048 Credits=2048x4DW=32768Bytes |
| Non-Posted Request Header (NPH) <br/>Non-Posted 请求 Header |
128 单位: 128 Credits=128*5DW=2560 Bytes |
| Non-Posted Request Data (NPD) <br/>Non-Posted 请求数据 |
作者无法给 Non-Posted 数据找到一个准确的 Credit 数量最大值。给出的单纯数据的 Credit 数量最大值为 2048。<br/>然而,一种更合理的计算的方法是使用 Non-Posted Header 来限制在 128 Credits 内,因为 Non-Posted 数据总是与 Non-Posted Header 相关联。 |
| Completion Header (CplH) <br/>完成包 Header |
128 单位: 128 Credits=128*4DW=2048 Bytes。这是对不发起事务的端口的限制(例如支持 Peer-to-Peer 的 RC 和 Switch)。 <br/>无限数量:初始 Credit 值=全 0。应用于发起事务的端口(例如不支持 Peer-to-Peer 的 RC 和 EP)。 |
| Completion Data (CplD) <br/>完成包数据 |
2048 单位: 值为设备支持多有 Function(8 个)的 Max_Payload_Size(4096 bytes)总和,总和为 8x4096=32768,除以 Credit 大小(4DW)。 <br/>2048 Credits=2048x4DW=32768Bytes <br/>无限数量:初始 Credit 值=全 0。应用于发起事务的端口(例如不支持 Peer-to-Peer 的 RC 和 EP)。 |
表 6‑2 流控通告最大值
6.3.2 无限 Credit(Infinite Credits)
可以注意到,如果流控 Credit 值为 00h,那么其意思就是拥有无限多的 Credit。在流控初始化之后,不会再进行任何的通告(advertisement)。发起事务的设备必须要保留足够的 buffer 空间,这些 buffer 空间用来存放执行拆分事务(split transaction)的过程中返回的数据以及状态信息。这些事务组合包括:
-
Non-Posted 读请求和返回的完成包数据
-
Non-Posted 读请求和返回的完成包状态
-
Non-Posted 写请求和返回的完成包状态
6.3.3 无限 Credit 通告的特殊用法
协议规范指出,当一个设备只实现了 VC0 时,需要有一些特别的考虑。例如,仅有的两种 Posted 写请求:IO Write 与 Configuration Write,二者仅允许使用 VC0。因此,Non-Posted 数据 buffer 并不会被 VC1-VC7 所使用,那么就可以为 VC1-VC7 宣告一个无限 Credit 值。然而 Non-Posted Header 仍然需要进行操作,所以 Header Credit 的值需要继续更新,而并非保持无限。
6.4 流量控制初始化(Flow Control Initialization)
6.4.1 整体说明(General)
在发送任何事务之前,都需要进行流控初始化(flow control initialization)。事实上,在流控初始化成功完成之前,TLP 是不能在链路上进行发送的。流控初始化会发生于系统中的每一个链路,其过程主要为链路两端设备之间的一次握手。这一过程会在物理层的链路训练(link training)完成后就开始进行。链路层观察 LinkUp 信号是否有效,获知物理层何时处于 Ready 状态,如图 6‑3 所示。
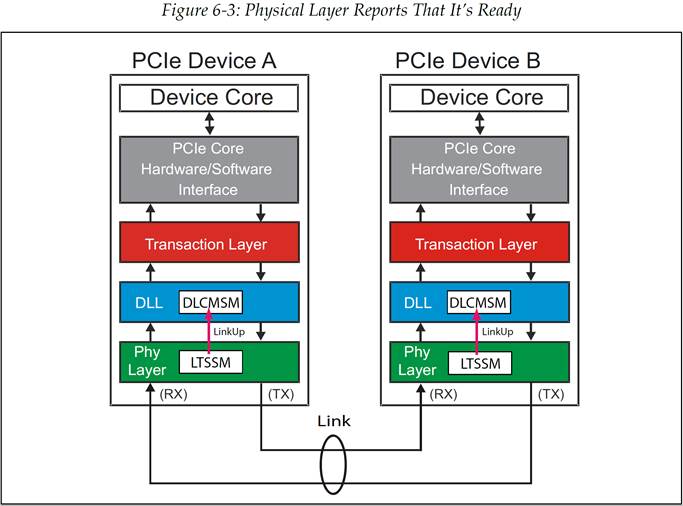
图 6‑3 物理层报告自己已经 Ready
一旦流量控制初始化开始,那么这个过程从根本上来说在各个虚拟通道(VC)上都是一样的,当一个 VC 被启用时,硬件就负责控制它的流量控制初始化过程。VC0 默认总是启用,因此它的初始化过程是自动的。这使得配置事务可以遍历整个拓扑结构,并进行枚举过程。其他的 VC 只有在配置软件对链路两端都进行了设置并且启用它们之后才会进行初始化。
6.4.2 流控初始化流程(The FC Initialization Sequence)
流控初始化过程涉及到链路层的 DLCMSM(Data Link Control and Management State Machine,数据链路控制与管理状态机)。如图 6‑4 所示,复位后状态机将处于 DL_Inactive 状态。在 DL_Inactive 状态中,会发出 DL_Down 信号,这个信号会作用于链路层和事务层。与此同时,也会在此状态中等待物理层的 LinkUp 信号,此信号是用于表示 LTSSM(Link Training and Status State Machine,链路训练和状态状态机)已经完成了工作,也就是物理层已经处于 Ready 状态。当物理层 Ready 后,将会使得 DLCMSM 跳转至 DL_Init 状态,它包含两级子状态用于处理流控初始化:FC_INIT1 和 FC_INIT2。
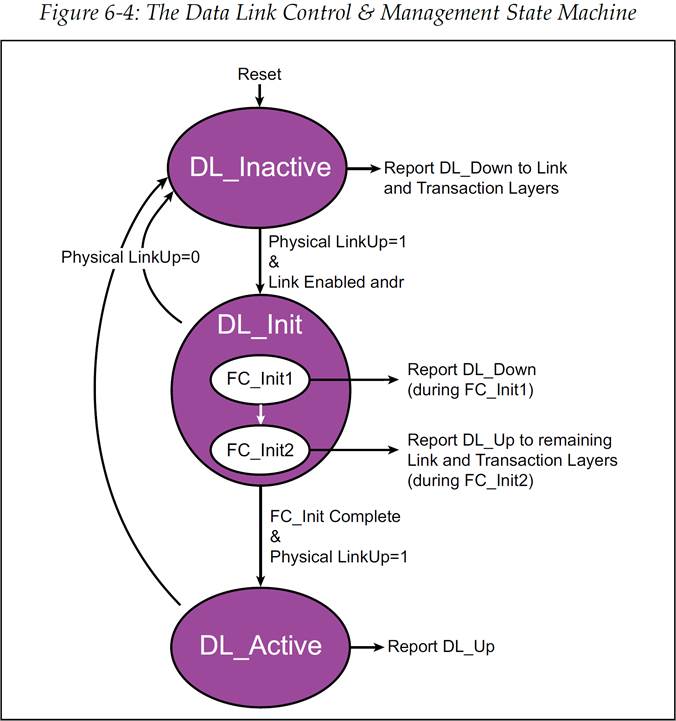
图 6‑4 DLCMSM 数据链路控制与管理状态机
6.4.3 FC_Init1 详细说明(FC_Init1 Details)
在 FC_Init1 状态中,设备会连续的发送一系列的 3 种 InitFC1 流控 DLLP 来通告它的接收 Buffer 大小(见图 6‑5)。根据协议规范,数据包必须按照这样的顺序来进行发送:Posted,Non-Posted,Completion 完成包,如图 6‑6 所示。协议规范中强烈建议频繁的重复这些 DLLP 的发送,这会使接收设备能够更容易的发现它们,特别是在当前没有 TLP 或者 DLLP 需要发送的情况下。
每个设备都需要从对端设备接收到这一系列 DLLP,这样它才可以将对端设备的 Buffer 空间大小记录下来。一旦设备已经发送出了自身的 Buffer 空间大小的值,并且接收到了足够次数的完整的 DLLP 序列,所谓足够次数是指,设备足以相信接收到的对端 Buffer 大小的值是正确的,那么此时设备就已经可以跳出 FC_INIT1 状态了。要进行跳出的操作,设备需要将接收到的值记录在传输计数器(transmit counter)中,置起一个内部的 flag 信号(FL1),然后就可以跳转到 FC_INIT2 状态来进行初始化操作中的第二步。
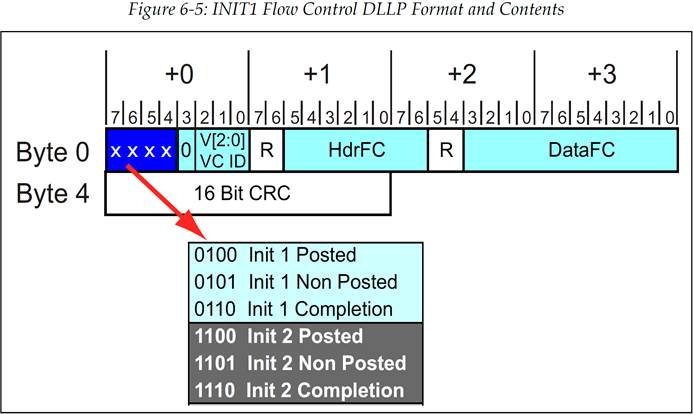
图 6‑5 INIT1 流控 DLLP 格式及内容
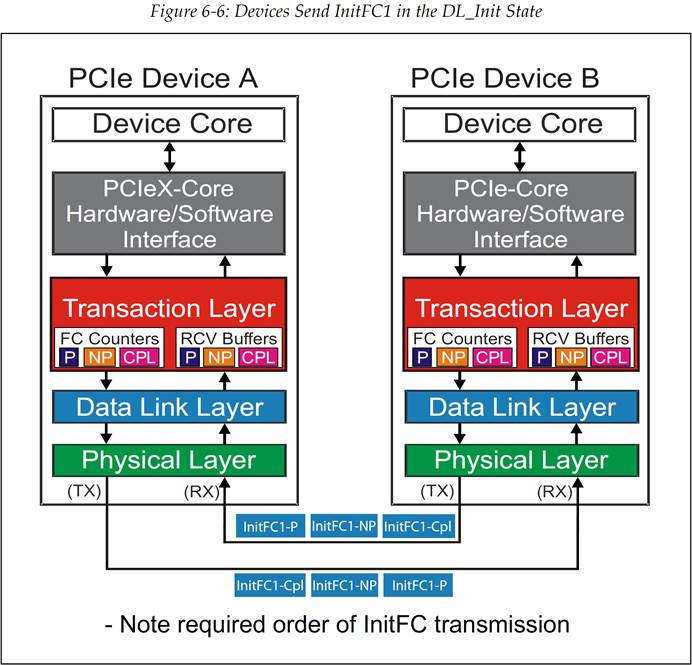
图 6‑6 设备在 DL_Init 状态下发送 InitFC1 DLLP
6.4.4 FC_Init2 详细说明(FC_Init2 Details)
在 FC_Init2 这个状态中,设备需要连续的发送 InitFC2 DLLP。发送 DLLP 的顺序和 FC_Init1 中一样,并且其中也包含了相同的有关 Credit 的信息,但是这些 DLLP 还有一个作用就是发送方用来确认流控初始化(FC initialization)已经成功。由于设备在 FC_Init1 状态中就已经寄存了对端的可用 Buffer 值,因此它不在需要任何关于 Credit 数量的信息,它在等待 InitFC2 DLLP 时会忽略传来的所有 InitFC1 DLLP。虽然对于链路另一端设备来说此时并没有完成初始化,但是设备可以在此时发送 TLP。初始化的完成与否是通过 DL_Up 信号来对事务层进行指示的。(见图 6‑7)
你可能会有疑问,初始化过程为什么还需要这个第二阶段呢?一个简单的回答是:链路两端的设备在完成流控初始化(FC Initialization)时需要的时间可能是不一样的,而这样两步的方法可以确保在较快的设备完成初始化后,较慢的那一端依然能够继续接收到需要的流控信息(FC Information)。
一旦设备接收到了任意 Buffer 种类的 FC_INIT2 数据包,那么它就会置起一个内部的 flag(FL2)。(这个操作不需要等待接收到所有种类的 FC_INIT2 数据包)注意,FL2 也可以在接收到一个 UpdateFC 包或者 TLP 之后被置起的。当链路两端的设备都完成了这些步骤并且都发送出了 InitFC2 DLLP 之后,DLCMSM 将会跳转至 DL_Active 状态,链路层初始化完成。
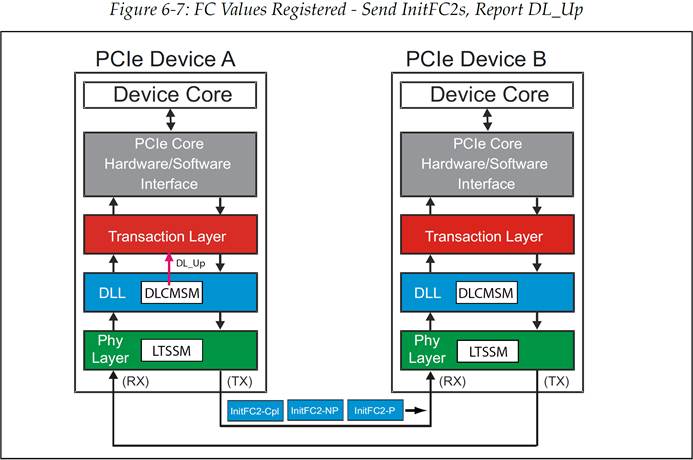
图 6‑7 FC 值已经寄存-接下来发送 InitFC2 并报告 DL_Up
6.4.5 FC_INIT1 和 FC_INIT2 的传输速率(Rate of FC_INIT1 and FC_INIT2 Transmission)
在协议规范中定义了发送 FC_INIT DLLP 之间的延时,如下:
- VC0:基于硬件进行流控的 VC0 要求 FC_INIT1 包和 FC_INIT2 包要 “以最大速率连续传输"。也就是说重发计时器(resend timer)设置的重发间隔值为 0。
- VC1-VC7:当软件启动了其他 VC(VC0 之外)的流控初始化时,FC_INIT DLLP 序列需要在“当没有其他 TLP 或者 DLLP 需要传输时”被重复发送。
- 需要注意,两组 DLLP 序列发送的起始时刻最多只能间隔 17us。
6.4.6 流控初始化协议违例
设备对流控初始化协议违例的检测是可选的。检测到的错误可以作为数据链路层协议错误进行报告。
6.5 流控机制的介绍(Introduction to Flow Control Mechanism)
6.5.1 整体说明(General)
协议规范定义了流量控制机制所要求的寄存器、计数器,以及一系列的机制用于报告(reporting)、追踪(tracking)和计算(calculating)一个事务是否可以被发出。这些元素并不是必需的,它们的实际实现是由设备的设计者来决定的。本节将介绍协议规范模型,并解释相关概念和对需求进行定义。
6.5.2 流控相关元素(The Flow Control Elements)
图 6‑8 说明了用于管理流量控制的元素。图中展示了在连路上单向传输的事务,而另一组这些流控元素则支持相反方向的传输。每个元素的主要功能都会再下面的内容中列出。虽然对于全部的 6 种接收 buffer 都重复有这些流控元素,但是为了简单起见,在本例子中仅考虑 Non-Posted Header 流控。
与管理流控相关的最后一个元素是流控更新 DLLP(Flow Control Update),它也是在链路正常传输期间唯一可使用的流控包。FC Update 包的格式如图 6‑9 所示

图 6‑8 流控元素
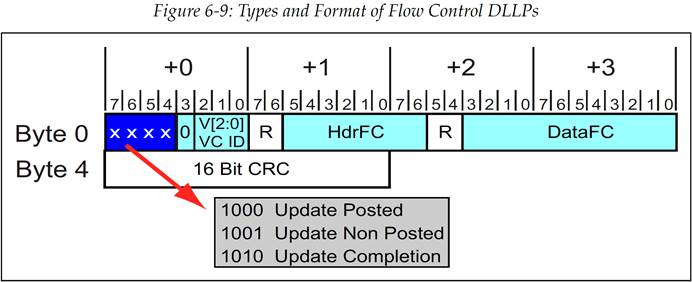
图 6‑9 流控 DLLP 的类型和包格式
6.5.2.1 发送方流控元素(Transmitter Elements)
-
事务等待缓冲区(Transactions Pending Buffer):把将要发送进统一虚拟通道的事务暂存起来。
-
Credit 消耗计数器(Credits Consumed counter):该计数器是记录发送给对端当前类型 Buffer 的所有事务的 Credit 总和(也就是消耗了接收端多少 Credit),这个计数值也可以被缩写成“CC”。
-
Credit 额度计数器(Credit Limit count):该计数器的初始值由对端接收者相应类型的 Buffer 大小而决定。在初始化之后,对端接收者会定期的发送流控更新包(FC Update),以便在接收方 Buffer 可用时更新流控 Credit。这个值可以被缩写为“CL”。
-
流控门控逻辑(Flow Control Gating Logic):它用于进行计算来确定对端接受者是否有足够的流控 Credit 来接收等待发送中的 TLP(Pending TLP,PTLP)。本质上来说,这个逻辑就是检查 CREDITS_CONSUMED(CC)加上下一个 PTLP 所需要消耗的 Credit 是否大于 CREDIT_LIMIT(CL)。协议规范中定义了下面的方程,以此来完成上述的检查,方程中所有的值的单位都是 Credit。
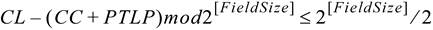
关于应用此方程式的例子,请参阅 6.6 中的“Stage 1 – Flow Control Following Initialization”一节。
6.5.2.2 接收方流控元素(Receiver Elements)
-
流控缓冲区(Flow Control Buffer):储存输入的 Header 或者数据。
-
Credit 分配计数(Credit Allocated):记录已分配(可用)的全部的流控 Credit 数量。它是由硬件进行初始化的,反映了已分配的流控 Buffer 的大小。这些 Buffer 会在事务到达时被填充,但是填充进去的事务最终都会被接收端取出,也就是从 Buffer 中移除。当它们被移除时,这部分的 Buffer 空间 Credit 数量将会被加到 CREDIT_ALLOCATED 计数值上。因此这个计数器会记录并表征当前可用的 Credit 数量。
-
已接收 Credit 计数器(Credit Received counter,optional):这是一个可选项,它用于记录进入流控 Buffer 的所有 TLP 的总 Credit 数量。当流控功能正常时,CREDIT_RECEIVED 计数值应该小于等于 CREDIT_ALLOCTED 计数值。如果并未满足这二者的“小于等于”条件,那么就会发生 buffer 溢出并检测到出错。协议规范推荐设计者实现这一可选的机制,并且需要注意的是这里若出现违例则应该将其视作是一个 Fatal Error,即非常严重的错误。
6.6 流控示例(Flow Control Example)
接下来将会以 Non-Posted Header 流控 Buffer 作为例子进行讲解,并尝试捕捉出在多种情况下流控实现的细微差别。对流控的讨论将会分为如下几个基本阶段:
-
阶段一:在初始化之后紧跟着传输一个事务,并对其进行追踪,以此来解释流控元素中的计数器和寄存器的一些基本操作。
-
阶段二:发送方发送事务的速度大于接收方能处理事务的速度,使得接收方 Buffer 被填满。
-
阶段三:当计数器翻转到 0(持续增大后回到 0),流控机制依然可以正常工作,但是需要考虑几个问题。
-
阶段四:接收方可以对 Buffer 溢出错误进行检查,这是一个可选项。
6.6.1 阶段一——初始化后的流控(Flow Control Following Initialization)
一旦流控初始化完成后,设备就已经准备好进行正常工作了。我们的示例中的流控 Buffer 大小为 2KB,且种类为 Non-Posted Header Buffer,因此 1 个 Credit 代表 5dwords 大小,也就是 20Bytes。这意味着可用的流控单位数量为 102d(66h)。图 6‑10 显示出了涉及到的流控元素,包括流控初始化后各计数器和寄存器的值。
当发送方准备好要发送一个 TLP 时,它必须首先检查流控 Credit。我们给出的例子会比较简单,因为发出的数据包有且仅有一个 Non-Posted Header,它永远只会需要 1 个 FC Credit 即可,并且我们也事先假设这个事务中不存在数据荷载。
关于 Header Credit 的检查使用的是无符号算术(2 的补码,2’s complement),它需要满足以下公式:

代入图 6‑10 中所示的值得到:
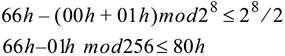
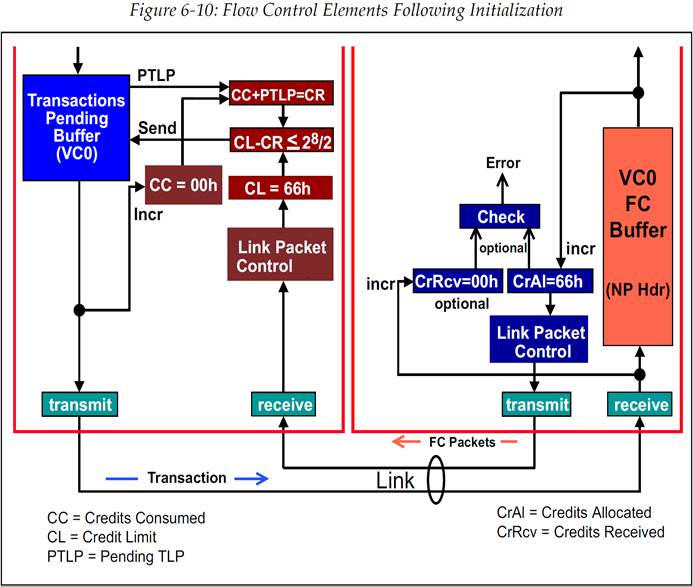
图 6‑10 初始化后的流控元素
在本例中,将当前 CREDITS_CONSUMED 计数值(CC)加上 PTLP 所需的 Credit(Header 需要 1 Credit,也就是 PTLP 所需的 Credit 数量=01h),以此来确定 CREDITS_REQUIRED(CR),也就是 00h+01h=01h。然后再用 CREDIT_LIMIT 计数值(CL)减去 CREDITS_REQUIRED(CR),这样就能确定是否有足够的可用 Credit。
下面的描述包含了对利用 2 的补码(就是计算机网络中熟知的补码,另一个 1 的补码其实是反码)进行减法的简要回顾。当使用 2 的补码进行减法计算时,将要减去的数先转换为反码(1 的补码)再加 1,这要就得到了减数的补码(2 的补码)。然后再将被减数与减数的补码(2 的补码)相加,并丢弃最高位进位。
Credit 检查:

CR 转换为 2 的补码:

CR 的 2 的补码加上 CL:

结果是否小于等于 80h 呢?是的。减法运算后的结果小于等于计数器最大值的一半,这里是用模 256 的计数器进行记录的,因此最大值的一半就是 128,满足此条件我们就认为接收 Buffer 有足够的空间,可以发送当前的数据包。这其中只使用一半的计数器值的做法可以避免潜在的计数错误的问题,参阅“Stage3—Counter Roll Over”一节。
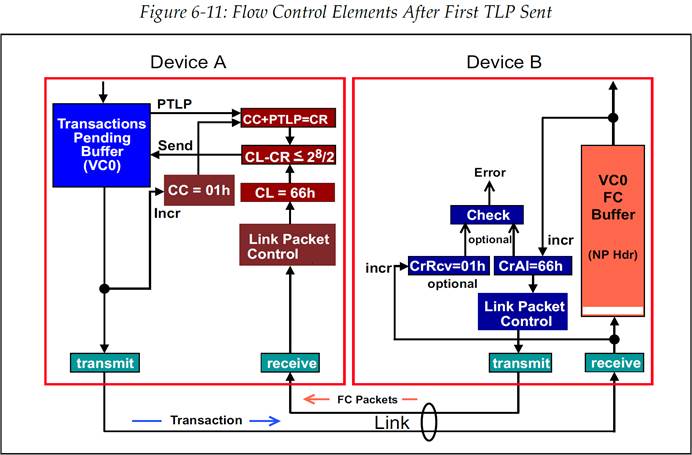
图 6‑11 第一个 TLP 发送后的流控元素
6.6.2 阶段二——流控 Buffer 已满(Flow Control Buffer Fills Up)
假设现在接收方已经有一段时间没有从流控 Buffer 中移除事务了,或许是 Device Core 繁忙,无法处理事务。最终流控 Buffer 完全被填满,如图 6‑12 所示。此时如果发送方又希望发送一个 TLP,那么它先进行流控 Credit 检查:
Credit Limit(CL)=66h
Credits Required(CR)=67h
进行 CL-CR 无符号减法运算,也就是减数转换为 2 的补码的加法运算:
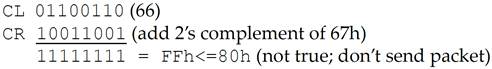
不难发现 FFh<=80h 并不成立,因此不能发送数据包。
这个通道会一直被阻塞,直到发送方接收到 Update Flow Control DLLP(更新流控 DLLP),这个 DLLP 将 CREDIT_LIMIT(CL)的值更新为 67h 或者更大的值。当新的值存入 CL 寄存器时,发送方的 Credit 检查就可以通过了,也就可以发送下一个 TLP 了(Header 只占 1 个 Credit)。
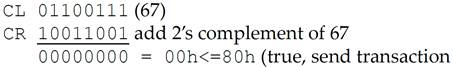
00h<=80h 成立,可以发送数据包。这里之所以 CREDIT_LIMIT 值加 1 就够用是因为我们是使用 Non-Posted Header 流控 Buffer,Header 只占 1 个 Credit。
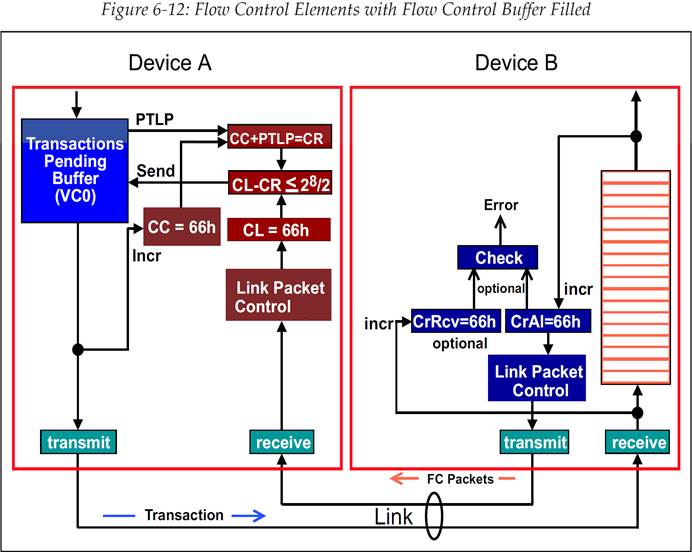
图 6‑12 流控 Buffer 填满后的流控元素
6.6.3 阶段三——计数器翻转为 0(Counters Roll Over)
由于 Credit Limit(CL)和 Credit Required(CR)计数只会向上增加,它们最终会翻转为 0。当 CL 翻转而 CR 还没翻转时,Credit 检查(CL-CR)就会出现较小值的 CL 减去较大值的 CR 的情况。然而,在使用无符号算术时,这种情况并不会引发问题。如前面的例子所描述的那样,当使用 2 的补码进行减法运算时,是可以得到正确的处理结果的。图 6‑13 展示了 CL 翻转前后,CL 与 CR 的值,以及 CL-CR 的 2 的补码减法运算结果。
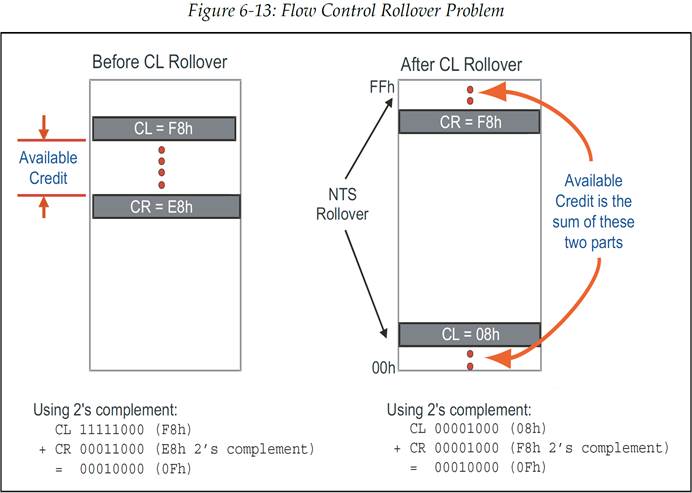
图 6‑13 流控计数器翻转问题
6.6.4 阶段四——流控 Buffer 溢出错误检查(FC Buffer Overflow Error Check)
尽管这是一个可选操作,但是协议规范还是推荐实现这个 FC Buffer 溢出错误检查机制。图 6‑14 展示了和溢出错误检查相关联的流控元素,包括:
这些元素使得接收方可以使用跟发送方相同的方式来记录流控 Credit。如果流控机制正确运行,那么发送方的 Credits Consumed 计数值(CC)永远不会超过它的 Credit Limit(CL),并且接收方的 Credits Received(CR)也永远不会超过它的 Credits Allocated 计数值(CA)。
若检测到下面的公式成立,那么就说明出现了溢出情况。注意公式中的 Field Size 对 Header 来说为 8,对数据来说为 12。
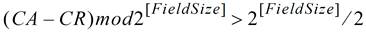
当公式成立时,说明发送至 FC Buffer 的 Credits 数量已经超过了可用的数量,也就是说发生了溢出。注意在 PCIe 1.0a 版本中定义的公式中使用的是≥而不是>。这是一个错误,因为 CA=CR(Credits Received)时并没有发生溢出。

图 6‑14 Buffer 溢出错误检查
6.7 流控更新(Flow Control Update)
当接收方的 Buffer 内有事务被移除时,也就说明这一部分 Buffer 空间又变为可用了,那么接收方就需要定期的用最新的流控 Credit 数量来更新对端设备。图 6‑15 给出了一个例子,示例中发送方原本由于 Buffer 已满的原因阻塞了 Header 事务的发送,而后接收方从流控 Buffer 中移除了 3 个 Header,这使得现在有可用的 Buffer 空间了,但是此时对端设备并不知道这件事。当 3 个 Header 从 Buffer 中移除时,CREDITS_ALLOCATED 计数值(CA)会从 66h 增加至 69h,这个新的计数值被报告给对端设备(发送方)的 CREDIT_LIMIT 寄存器,报告的方式是使用流控更新包(FC Update packet)。一旦 CREDIT_LIMIT 被更新,发送方就可以继续发送 TLP 了。
需要特别指出的一点是,这里更新报告的是 CREDITS_ALLOCATED 寄存器的实际值。其实我们本可以只报告寄存器值的变化量,比如“Non-Posted Header +3 Credits”,但是这种表示会存在一个潜在的问题。为了理解这其中所含的风险,我们需要考虑如果包含了寄存器变化增量信息的 DLLP 因为某些原因造成了丢失,此时会发生什么。对于 DLLP 来说是没有 replay 机制的,如果出现了错误那么处理方式就是简单的把 DLLP 丢弃。在这种情况下,增量信息将会丢失,并且没有方法恢复它。
反过来说,如果报告的是寄存器的实际值而不是增量,那么在 DLLP 传输失败时,下一个 DLLP 依然可以完成计数值的同步更新。虽然这种情况有时会浪费一些时间,比如发送方需要在一个 DLLP 发送失败时等待下一个 DLLP 来更新流控 Credit,但是并不会有信息的丢失出现。

图 6‑15 流控更新示例
6.7.1 流控更新 DLLP 格式和内容(FC_Update DLLP Format and Content)
回想一下,流控更新包与流控初始化包一样,包含两个 Credit 字段,一个是 Header Credit 字段,一个是 Data Credit 字段,如图 6‑16 所示。接收方报告在 HdrFC 和 DataFC 字段的 Credit 值可能已经更新了很多次,也有可能自从上次发送更新包后就没有变过。

图 6‑16 流控更新包的格式和内容
6.7.2 流控更新频率(Flow Control Update Frequency)
针对流控更新 DLLP 应该如何发送,协议规范定义了各种规则以及建议的实现方式。它们是为了:
— 需要足够频繁的报告 Credit 信息,以此来避免事务阻塞
— 希望减少流控更新 DLLP 所需要的链路带宽
— 选择最优的 Buffer 大小
— 选择最大的数据荷载大小
流控更新仅在链路处于活跃状态(active state,L0 or L0s)时才能使用。所有其他的链路状态表示更加积极的电源管理,它具有更长的恢复时延。
当一个流控 Buffer 已经满到无法接收最大的数据包时,协议规范要求要在 Buffer 出现更多可用空间时立即发送一个 FC_Update DLLP。存在两种情况:
-
最大数据包大小=1Credit。当数据包的发送由于非无限的 NPH(Non-Posted Header)、NPD(Non-Posted Data)、PH(Posted Header)和 CplH(Completion Header)这些种类的 Buffer 已满而被阻塞时,若此时有 1 个或多个的 Credit 变为可用(已分配),那么流控更新包(UpdataFC Packet)必须要被安排传输。
-
最大数据包大小=Max_Payload_Size。对于非无限的 PD 和 CplD 的 Credit 类型,流控 Buffer 空间可能会减小到无法发送最大数据包的程度。在这种情况下,当 1 个或多个的 Credit 变为可用(已分配),流控更新包必须要被安排传输。
6.7.2.2 流控更新 DLLP 间最大延时(Maximum Latency Between UpdateFC)
每种 FC Credit 类型(非无限)的流控更新包安排发送的频率至少要达到每 30us(-0%/+50%)发送一次。如果设置了控制链路寄存器(Control Link Register)内的扩展同步位(Extended Sync bit),那么安排更新的频率必须不低于 120us(-0%/+50%)一次。注意,实际安排发送流控更新包的频率可能要比协议规范中要求的更频繁。
6.7.2.3 基于 Payload Size 和链路宽度计算更新频率
协议规范中提供了一个公式用于计算更新频率,这个计算是基于最大 Payload Size 以及链路宽度的。在下面展示的公式中,使用符号时间(symbol time)来定义流控更新的发送间隔。作为参考,1 个符号时间的定义为传输 1 个 symbol 所需要的时间,Gen1 为 4ns,Gen2 为 2ns,Gen3 为 1ns。表 6‑3、表 6‑4、表 6‑5 展示了每种速率下的原生未调整的流控更新参数值。(译注:UF 意为 UpdateFactor,原文中的 FC 应该是写错了,应该也是 UF)
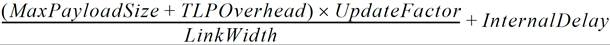
-
最大荷载大小(MaxPayloadSize):这个值在设备的控制寄存器(Control Register)中的 Max_Payload_Size 字段。
-
TLP 开销(TLP Overhead):常数值(28 symbol)表示消耗链路带宽的附加 TLP 组件(TLP 前缀 Prefix、序列号 Sequence Number、包头 Header、LCRC、组帧符号 Framing Symbol)。
-
更新因子(UpdateFactor):在两个相邻流控更新包被接收到的中间间隔的这段时间里,所能发送的最大大小 TLP 的数量。这个数字是为了平衡链路带宽效率和接收 Buffer 大小——因为这个值会随 Max_Payload_Size 和链路宽度而发生变化。
-
链路宽度(LinkWidth):链路所使用的通道(Lane)数量。
-
内部延时(InternalDelay):是一个常数值,为 19 个符号时间(symbol time),表示接收到 TLP 并发送 DLLP 所需要的内部处理延迟。
公式中定义的关系表明,发送流控更新包的频率随链路宽度增加而减少,建议使用计时器来触发流控更新包的调度发送。需要注意,这个公式不考虑接收方或是发送方在 L0s 电源管理状态时相关的延时(译注:前面提到过仅在 active 状态才可以使用流控更新)。
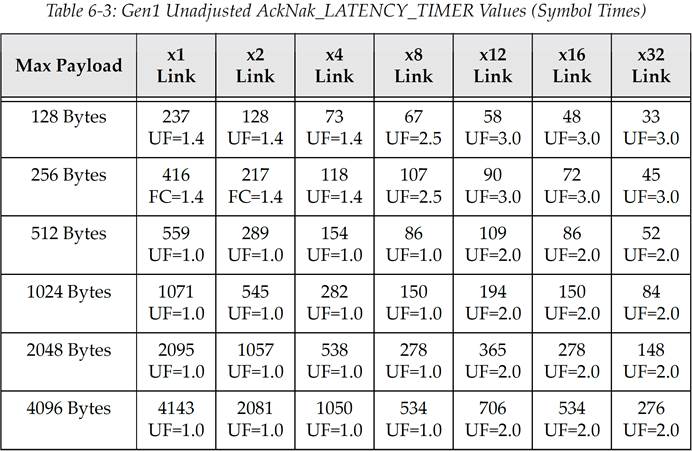
表 6‑3 PCIe Gen1 原生未调整的 AckNak_LATENCY_TIMER 值(单位为 Symbol time)
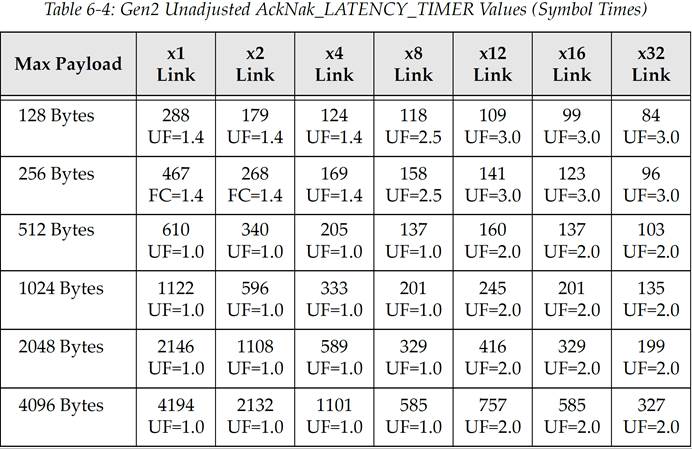
表 6‑4 PCIe Gen2 原生未调整的 AckNak_LATENCY_TIMER 值(单位为 Symbol time)
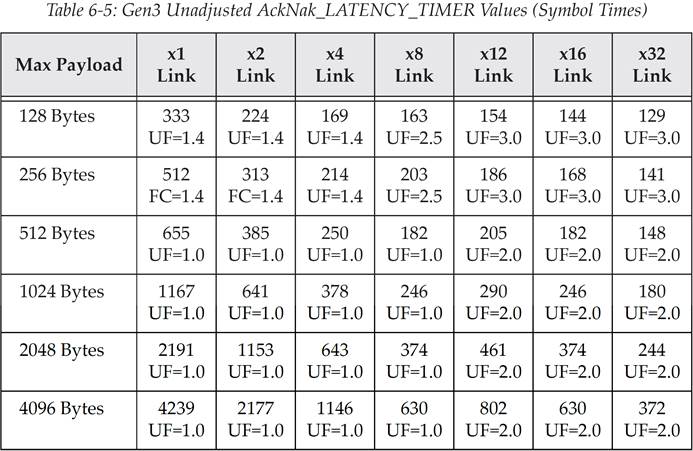
表 6‑5 PCIe Gen3 原生未调整的 AckNak_LATENCY_TIMER 值(单位为 Symbol time)
译注:译者对上面三个表格进行举例说明,选取 PCIe Gen1,Max Payload=256,x2 Link,代入公式得到((256+28)*1.4/2)+19=217.8,不难发现就是对应表中 217 这个值。
而对于 Gen2、Gen3 可能发现不符合公式,其实不难发现 Gen2=Gen1+51,Gen3=Gen2+45,这应该是书中没有提供一些常数参数的原因,总之 Gen2 表格内的值都等于 Gen1 对应的值加上 51;Gen3 表格内的值都等于 Gen2 对应的值加上 45。
协议规范认识到这个公式其实对于许多应用场景的使用是不恰当的,比如那些使用大块数据流的应用。这些应用可能会要求实际 Buffer 的大小要大于规范中给出的大小,以及使用更复杂的更新策略,以此来优化性能和降低功耗。由于解决方案依赖于具体应用的特定需求,因此协议规范中并没有提供此类策略的定义。
6.7.3 错误检测计时器——一个软要求(Error Detection Timer——A Pseudo Requirement)
协议规范中为流控包定义了一个可选的超时(time-out)机制,并且强烈建议实现它,目前它只是一个软要求,但是在未来版本的协议中它可能会成为一个硬性的要求。对于一种给定的 Credit 类型,它的两个流控包之间的最大延时间隔为 120us,而对于超时机制来说超时界限为 200us。对于每种流控 Credit 类型(Posted、Non-Posted、Completion),都各自有单独的超时计时器,且每个计时器都在收到相应类型的流控更新 DLLP 时进行复位。需要注意,与无限流控 Credit 相关联的超时计时器一定不能报告错误。
除开无限 Credit 的情况之外,其他情况下的超时意味着链路存在一个严重的问题。如果超时发生了,那么物理层就会被通知进入恢复状态(Recovery state),并重新进行链路训练,以期望清除错误状态。超时计时器的特性包括:
-
仅在链路处于 active 状态(L0 or L0s)才进行工作。
-
最大时间限为 200us(-0%/+50%)
-
当接收到初始化(Init)或者流控更新包(Update FCP)时,计时器就会复位。或者可选的,也可以在接收到任何 DLLP 时都复位计时器。
-
超时(Timeout)会强制物理层进入 LTSSM(链路训练和状态状态机,Link Training and Status State Machine)的恢复状态(Recovery State)。
原文: Mindshare
译者: Michael ZZY
校对: LJGibbs
欢迎参与 《Mindshare PCI Express Technology 3.0 一书的中文翻译计划》
https://gitee.com/ljgibbs/chinese-translation-of-pci-express-technology


 发表于 2025-11-22 10:49:05
发表于 2025-11-22 10:49:05